Mary Had a Little Spam
Thursday, February 11, 2016 · 3 min read
I didn’t check the little box that allows colleges to send me promotional materials on the PSAT. I didn’t even enter an email address. But I still get dozens of mail—both physical and electronic—every day. It’s almost flattering.
All this email is a dataset, and so as a dutiful data nerd, I felt compelled to do something with it. Here’s the result, for the impatient:

An SVG is here if you want to make a printout or poster or album cover or pillow cover or whatever with this.
I feel compelled to say more about how to make this kind of image, lest I forget in the future.
The first step is to collate all the college spam and export it somehow. So, it all begins with a Gmail inbox search. Fortunately, I had the foresight to move all of my college spam to the “Promotions” category as it came in, and I get hardly any other promotional mail. So it was simply a matter of searching my inbox for messages delivered after the PSAT.

Your mileage may vary.
Next, you select all conversations by hitting the checkbox on top:

Now, you attach a “label” to them. I called my label college-spam:
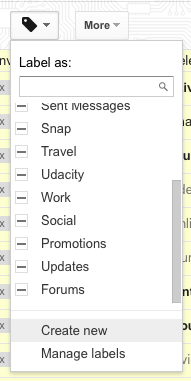
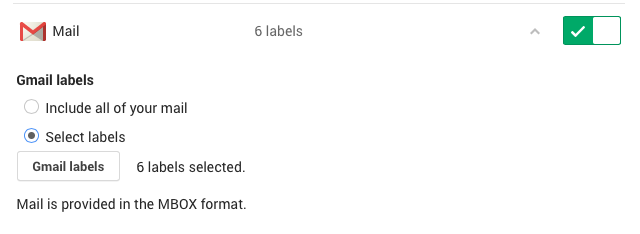
Finally, you head over to Google Takeout to export your email. Select just that label to expedite the process (you can select more than one if needed):
You should get an email in a couple of minutes with a link to download the archive.
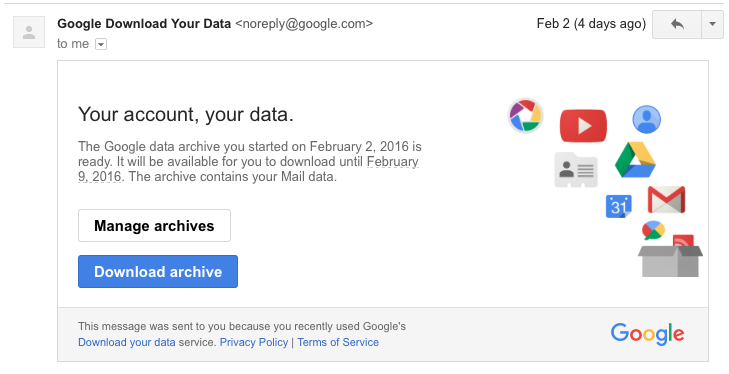
If you download and unzip it, you get a Mail/ directory containing an mbox
file whose name is the label you selected. Excellent.
The next step is to parse the mbox file. Python, as usual, has a module for
that, and before you can say “Beautiful Soup”, it can parse out the body of
each email in the archive, prune out style and script tags, extract the
plaintext, and print it out:
import mailbox
import bs4
mbox = mailbox.mbox('college-spam.mbox')
text = ''
def handle(s):
global text
soup = bs4.BeautifulSoup(s, 'html.parser')
for elem in soup.findAll(['script', 'style']):
elem.extract()
text = text + '\n' + soup.get_text()
for msg in mbox:
pyl = msg.get_payload(decode=True)
if pyl is None:
pyl = msg.get_payload()
if type(pyl) == list:
p = pyl[0]
q = p.get_payload(decode=True)
if q is not None:
handle(q)
else:
r = p.get_payload()
if type(r) == list:
handle(str(r[0]))
else:
handle(r)
else:
handle(pyl)
pass
print text.encode('utf8')
Email formats are complicated, and you’ll probably have to tweak the code above if the colleges that target you decide to use more obscure features.
Until then, the plan is to copy all that text:
$ python extract_words.py | pbcopy
and paste it into Jason Davies’ wonderful wordcloud workshop.
Ta-da!
P.S. Jacob Harris writes, “word clouds considered harmful”. I agree. This whole exercise isn’t really meant to be insightful—though if it leads you to an insight anyway, please do share!
P.S.S. I ran some markov chain generation on the corpus of text. Some highlights:
I received your contact information from the Student Search Service of the Milky Way.
You are cordially invited to take our online quiz, which can be tough.
Powered by hydrogen fuel cells, it sailed down the path of some of our financial aid program.
What are the factors that make you stand out from your iPhone or iPad?
During football games, you can see the future.
P.S.S.S. I got four more college emails while typing out this post. Sigh.